Paper-StyleGAN-V1
A Style-Based Generator Architecture for Generative Adversarial Networks
Accept:CVPR2019
code:github上一搜一大把(官方非官方,tf或者pytorch)
Problem:
生成更加真实多样且高清的图像
Framework
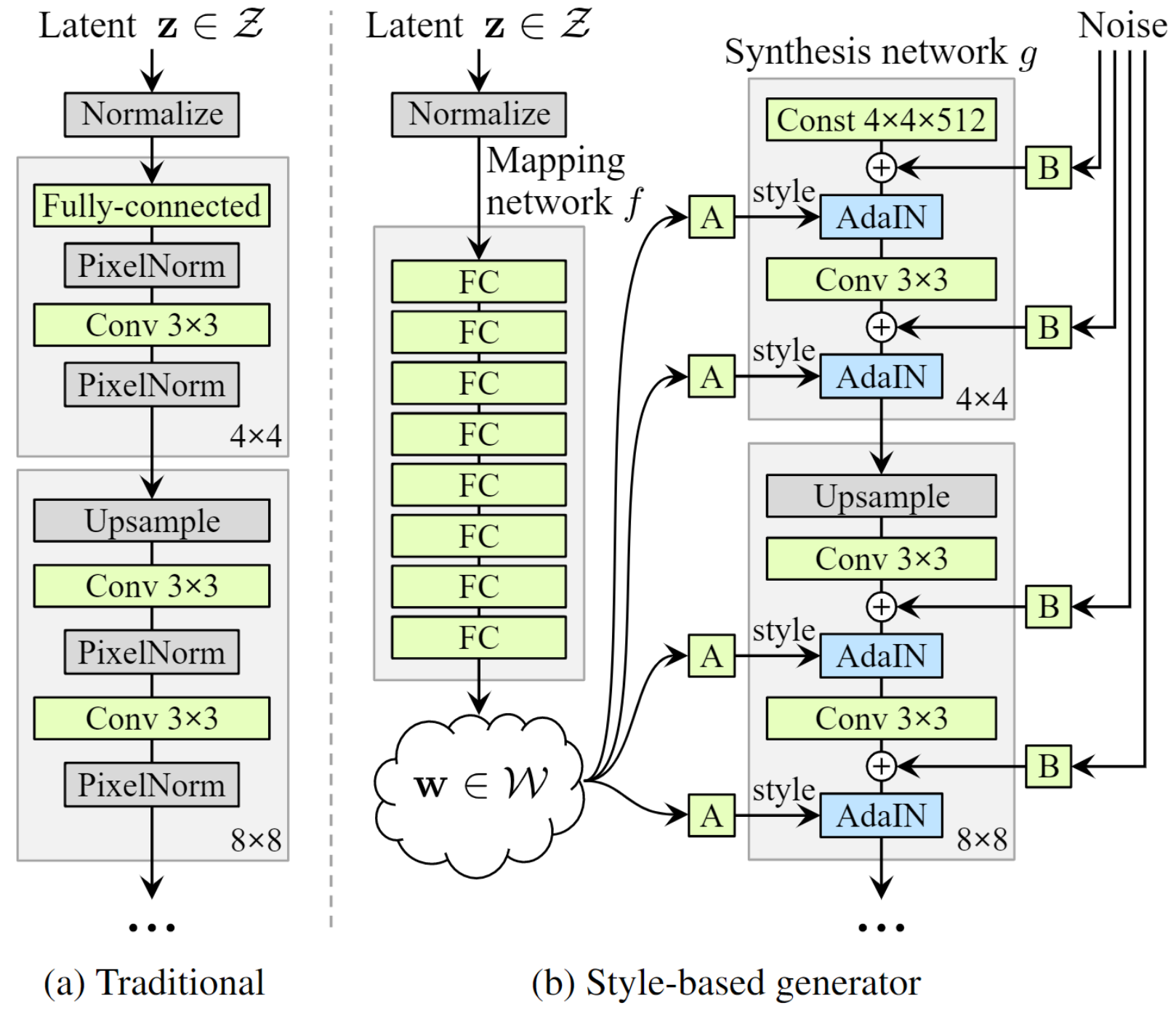
- 上图(a)为ProgressiveGAN(Progressive growing of GANs for improved quality, stability, and variation),作者就是在这篇的基础上进行改进;
- 上图(b)为StyleGAN的框架。
- 隐空间变换
首先通过8层的FC将随机采样的z改为了w,这样做的好处就是一般z都是从高斯分布进行采样,但是实际上高斯分布和真实数据的分布是不同的,因此将z变换到w空间能更好的对生成网络进行一个控制(个人觉得就是一个hard变为soft的过程,原先的先验采样z太hard了,如果转换到w空间,就能更好地拟合出真实样本的部分) - 生成网络
生成网络的输入不再是z,而是三部分,分别为上图(b)的Const 4×4×512,AdaIN变换的参数A(由w得到)以及随机噪声B。生成网络一共有9个块[4×4, 8×8, .., 1024×1024],每个块中有两层卷积(除了第一层),最后一层使用1×1卷积来转换通道数。
Style Mixing

采样两个z,z1和z2,再经过Mapping网络得到w1和w2
- (4×4-8×8)两个块使用SourceB的w,其余块使用SouceA的w
修改高级语义,比如姿势,发型,脸型和眼镜等,而像一些眼睛,头发光线等则保持不变
- (16×16-32×32)两个块使用SourceB的w,其余块使用SouceA的w
继承了B的较小比例的面部特征,比如发型,睁开/闭上的眼睛,而A的姿势,脸型和眼镜则保留下来
- (64×64-1024×1024)两个块使用SourceB的w,其余块使用SouceA的w
主要是一些颜色和细微结构的变化,整体的语义保持不变
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 xuedue!
相关推荐

2021-09-19
Paper-Stylegan-Image2StylegGAN
Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?Accept: 2019ICCV Problem:基于优化(optimized-based)的StyleGAN反转 Framework提出w+空间。即优化的latent code由原先stylegan的w变为w+(原先stylegan的w空间是通过复制然后送入styleblock进行调制,即18个w是完全相同的) LOSS perceptual loss and pixel-wise MSE loss$$w^∗ = \min_{w}L_percept(G(w), I) + \frac{λ_{mse}}{N}{\begin{Vmatrix}G(w) −I\end{Vmatrix}}_2^2$$ perceptual loss$$L_{percept}(I_1, I_2) = \sum_{j=1}^4\frac{λ_j}{N_j}{\begin{Vmatrix}F_j (I_1) −F_j (I_2)\end{Vmatrix}}_2^2$$perce...

2021-09-12
GAN Prior Embedded Network for Blind Face Restoration in the Wild
Paper:GAN Prior Embedded Network for Blind Face Restoration in the WildAccept:CVPR2021Code Problem:野外人脸复原(Blind face restoration),属于人脸复原任务中的一种,类似于超分,inpainting等工作。文章为了解决野外人脸的退化复杂性(噪声,缺损,分辨率低等),提出了解决方法。 Framework在原先的styelgan中,需要W和noise,也就是调制模块中的A和B。 w:将W修改为encoder得到的z,再经过mapping网络得到W。 noise:使用encoder中的浅层空间信息,同时这里作者将原先直接add的方式修改为concat,并在后续的实验中验证这两种方式的优劣。通过这种方法,作者认为可以比较好地结合全局信息(w,也就是z,感受野更大)和局部信息(noise,感受野更小),从而使得生成图像的质量更好。和之前基于stylegan的方法不同的是,作者这里对stylegan进行了finetune。
2021-09-19
Paper-FaceAging-Survey
Age simulation for face recognitionAccept:2006ICPR首先使用形状和纹理矢量通过在形状或纹理的本征空间中投影面部图像来表示面部图像。 然后结合年龄函数和年龄分类法对年龄进行估计。 并且我们使用估计的年龄,典型的向量创建函数和原始测试图像的特征向量来生成目标年龄的合成特征向量。 最后,我们重建了特征空间中的形状和纹理,并结合起来以在目标年龄合成面部图像。 A Compositional and Dynamic Model for Face AgingAccept:2009IEEE Transactions on Pattern Analysis and Machine Intelligence组成模型通过分层的“或”图表示每个年龄组中的面孔,其中“与”节点将面孔分解成描述对年龄感知至关重要的细节(例如头发,皱纹等)的部分 Age Synthesis and Estimation via Faces: A SurveyAccept:2010IEEE transactions on pattern analysis and machine ...
评论